Selenium을 맛봤으니 이제는 실습을 해야 할 차례이다.
Selenium은 다양한 웹 브라우저를 조작할 수 있는 라이브러리이다. 이 때, Selenium이 웹 브라우저를 조작하기 위해서는 각 브라우저마다 해당 브라우저를 제어할 수 있는 드라이버가 필요한데, Chrome 웹 브라우저를 조작하기 위해서는 ChromeDriver가 필요하다. 따라서, Selenium을 사용하기 위해서는 ChromeDriver를 다운로드하여 설치해야 한다.
셀레니움은 다양한 언어로 사용할 수 있는데, 자바, 파이썬 등에서 가장 많이 사용된다.
험난했던 chrome web browser 버전 맞추기
이전에 (한참 전…) 에 selenium을 찍먹했을 때는 https://chromedriver.chromium.org/downloads 이곳에서 크롬 웹브라우저를 설치할 수 있었다. 내가 다시 접한 자료들에서도 이곳에서 다운받으라고 하기에 내 크롬 버전이 뭔지도 모르고 가장 최신이라는 94.0.4606.41 을 설치했는데…
계속되는 오류에 지쳐가던 중 내가 사용하는 크롬 버전이 115버전이라는 걸 알게되었다.
https://googlechromelabs.github.io/chrome-for-testing/
크롬드라이버 115.0.5790.170은 여기서 다운받을 수 있다. STATUS가 X로 되어있는 경우도 있는데 이러면 안된다는거다 ;; 기다려야지 뭐
from selenium import webdriver
from selenium.webdriver.chrome.service import Service
from selenium.webdriver.common.by import By
from selenium.webdriver.support.ui import WebDriverWait
from selenium.webdriver.support import expected_conditions as EC
chromedriver_path = "/Users/inseoulmate/Downloads/chromedriver-mac-arm64/chromedriver"
service = Service(chromedriver_path)
driver = webdriver.Chrome(service=service)
driver.get("<https://www.genie.co.kr/chart/top200>")
wait = WebDriverWait(driver, 10)
wait.until(EC.presence_of_element_located((By.CLASS_NAME, "list-wrap")))
chart_items = driver.find_elements(By.CSS_SELECTOR, ".list-wrap > tbody > tr.list")
for item in chart_items:
rank = item.find_element(By.CLASS_NAME, "number").text
title = item.find_element(By.CSS_SELECTOR, ".info .title").text
artist = item.find_element(By.CSS_SELECTOR, ".info .artist").text
print(f"{rank}. {title} - {artist}")
# 셀레니움 웹 드라이버 종료
driver.quit()
먼저 코드 전문이다
1. 필요한 것 불러와주기
from selenium import webdriver
from selenium.webdriver.chrome.service import Service
from selenium.webdriver.common.by import By
from selenium.webdriver.support.ui import WebDriverWait
from selenium.webdriver.support import expected_conditions as EC
Selenium 라이브러리 자체를 임포트해준다.
webdriver : 웹 드라이버를 제어학디 위한 모듈이다. 웹 드라이버는 브라우저를 제어하고 웹 페이지에 엑세스하는데 사용된다.
Service : 웹 드라이버를 실행시키는 데 필요한 서비스를 관리하는 클래스이다. 특정 드라이버를 실행하기 위해 사용된다.
By: 웹 요소를 찾는 방법을 지정하기 위한 클래스이다. By.CLASS_NAME, By.CSS_SELECTOR, 등과 같은 방법을 사용하여 웹 요소를 식별한다.
WebdriverWait : 웹 드라이버를 통해 웹 페이지가 특정 조건을 만족할 때까지 기다리기 위한 클래스이다. 웹 요소의 출현이나 속성 등을 기다리는 데 사용된다 .
expected_conditions : 웹 요소가 특정 조건을 만족하는지 확인하기 위한 클래스이다
EC.presence_of_element_located , EC.visibility_of_element_located 등과 같은 조건을 사용했다.
2. 크롬 드라이버 설정해주기
chromedriver_path = "/Users/inseoulmate/Downloads/chromedriver-mac-arm64/chromedriver"
service = Service(chromedriver_path)
driver = webdriver.Chrome(service=service)
크롬드라이버가 어디 있는지도 찾아야 한다. 이거 찾느라 꽤나 오래 걸렸다. 보통 다운로드에 있다.
절대경로를 복사해서 붙여넣어주면 된다 .
3. 링크 연결하기
driver.get("<https://www.genie.co.kr/chart/top200>")
다음 나는 지니뮤직의 1위부터 100위까지를 스크래핑할거기에 차트 링크를 넣어주었다.
4. 정보 스크래핑하고 변수에 저장하고 출력하기
wait = WebDriverWait(driver, 10)
wait.until(EC.presence_of_element_located((By.CLASS_NAME, "list-wrap")))
chart_items = driver.find_elements(By.CSS_SELECTOR, ".list-wrap > tbody > tr.list")
for item in chart_items:
rank = item.find_element(By.CLASS_NAME, "number").text
title = item.find_element(By.CSS_SELECTOR, ".info .title").text
artist = item.find_element(By.CSS_SELECTOR, ".info .artist").text
드라이버 객체를 최대 10초까지 기다리며, 해당 시간 내에 “list-wrap” 클래스가 웹페이지에 나타날 떄까지 기다린다. 이 요소는 음악 차트 목록을 감싸는 부모 요소이다 .
BY.CSS_SELECTOR를 사용해 CSS선택자를 이용하여 해당 요소들을 찾고 반복문을 실행해주었다. 이후 item.find_element를 사용하여 요소 내에서 순위, 제목 및 아티스트 정보를 해당 요소들에서 찾아낸다. 이 정보들은 ‘rank’ , ‘title’, ‘artist’ 변수에 저장된다.
나머지는 print 함수를 이용해 출력하는것과 , 드라이버를 종료하는 것으로 마무리된다.
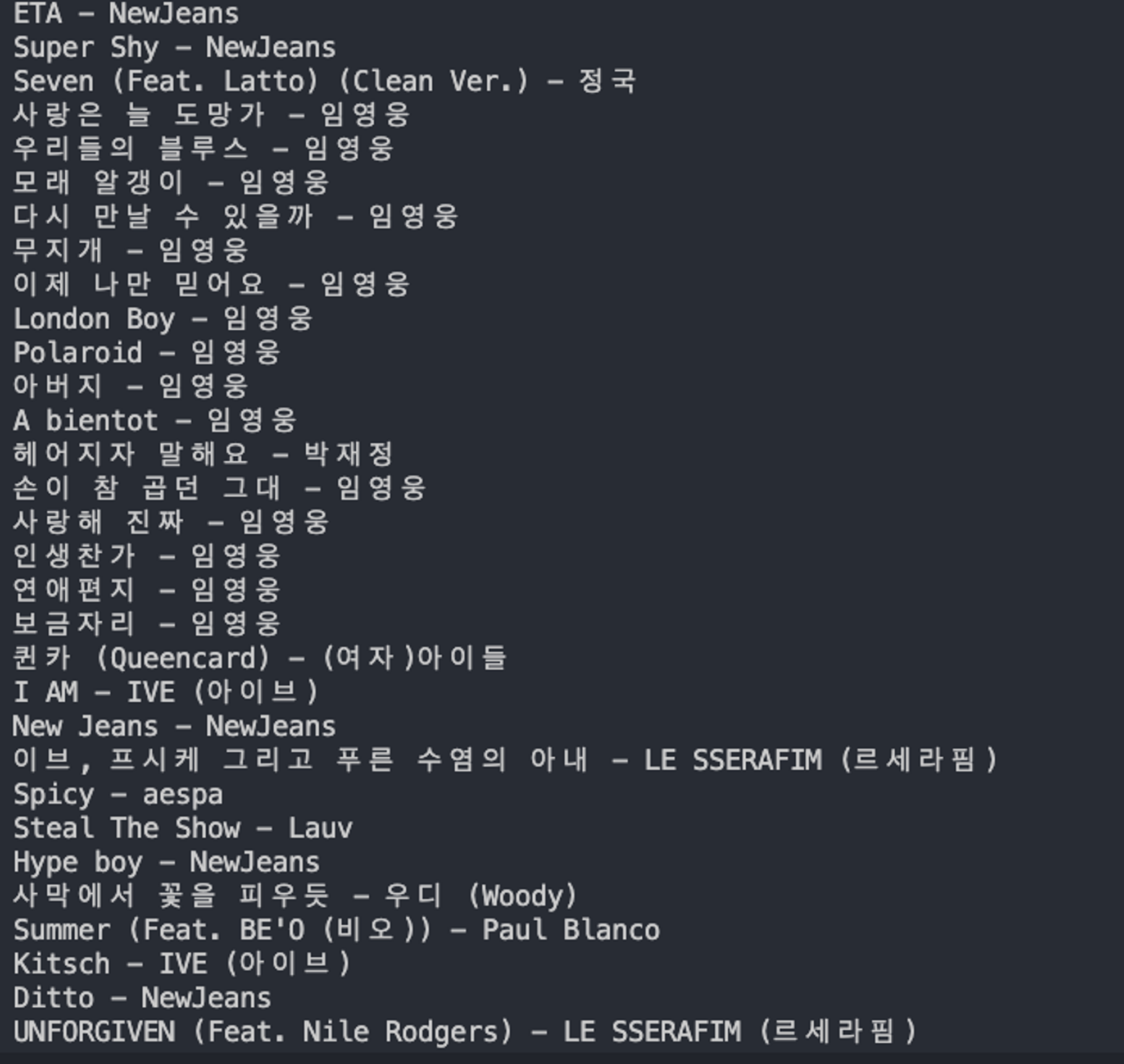
이렇게 잘 출력되었다. 개인적으로 뉴진스-ETA 노래 너무 좋다. 안 들어본 사람 있으면 꼭 들어봤으면 좋겠다.
'2023 공부한것들' 카테고리의 다른 글
| 8. selenium 실습하기 - 네이버 로그인 자동화 (0) | 2023.08.08 |
|---|---|
| 7. selenium 실습하기 - 네이버 뉴스 스크래핑 (키워드 TOP 10까지) (0) | 2023.08.08 |
| 5. 웹 크롤링과 스크래핑 로드맵 (0) | 2023.08.07 |
| 4. selenium을 공부해보자 (0) | 2023.08.07 |
| 3. 기초적인 웹 검색 기술과 검색엔진의 사용법 (0) | 2023.08.07 |