암호화를 담당하는 부분의 로직을 보고 보고 보고 또 봤다. 아니 세상에. 암호화 키를 생성하고 저장하는 로직에 큰 문제점이 있었다. 암호화 키는 앱이 설치될때마다 생성되어야 하는데 이 키가 여러번 생성되어서 중복되는 문제가 있었다. 서버에서는 암호화된 데이터를 복호화할수 없었고, 이러한 문제가 생겨버린 것이다.
Singleton Pattern : ‘PaymentService’를 싱글톤 패턴으로 구현하여 인스턴스가 하나만 생성되도록하였다. 이렇게 하면 암호화 키도 한 번만 생성된다
AsyncStorage : 생성된 암호화 키를 로컬에 저장하여 앱이 재시작될때마다 동일한 키를 사용하도록 했다. 이를 위해 @react-native-async-storage/async-storage 라이브러리를 사용했다
초기화 로직 변경 : ‘PaymentService’의 초기화 로직에서 암호화 키를 생성하는 대신, 로컬 데이터베이스에서 불러와 사용하도록 변경해주었다. 키가 없을 경우에만 새로 생성했다.
아마도 로컬로 저장하는것도 방법인 것 같다. 생성된 암호화 키는 로컬 데이터베이스, 예를 들면 AsyncStorage
암호화는 데이터 보호를 위해 꼭 필요한 과정이다. 특히 결제나 인증과 같은 중요한 트랜젝션에서는 데이터의 무결성을 보장하기 위해 암호화가 필수이다. 리엑트 네이티브에서도 이러한 암호하 처리가 필요하고, 암호화 키를 안전하게 관리하는 것 또한 중요한데, 진짜 나 정신차리자 .
컴포넌트의 재사용성 진짜 중요하다. 최적화와 너무 깊게 연관되어 있기 때문이다. 이번 프로젝트 진행 중 상품 목록 페이지를 개발하면서, 각 상품 카드를 표시하는 부분을 여러 곳에서 사용하여야 했다. 이러한 상황에서 재사용 가능한 컴포넌트를 어떻게 설계하고 최적화하는지에 대한 고민을 많이 하게 되었다.
재사용성을 높이기 위해 컴포넌트들을 작은 단위로 분류하고 props를 통해 데이터를 동적으로 전달하는 방식으로 개발했다. 또한, React.memo 나 PureComponent 와 같은 최적화 기술을 활용하여 불필요한 리렌더링을 방지하고 성능을 향상시키는 방법을 생각해봐야 할 것 같다
상태 관리의 복잡성과 미들웨어
위에서 언급한 Redux를 사용하여 상태 관리를 하는데 복잡하더라. 특히 비동기 작업과 관련된 부분이 어려웠다. . Redux Thunk, Redux Saga, Redux Observable 등 미들웨어가 너무 많아서 어떤걸 선택해야 할지 혼란스러웠다. 비동기 작업을 효과적으로 처리하고 상태 관리의 복잡성을 줄이기 위해 Redux Thunk 를 활용하여 API 호출 및 데이터 처리를 구현해보았다. 고르기 진짜 힘들었따
상태 최적화와 선택적 리렌더링
→ 대규모 앱에서는 성능 최적화가 중요한 이슈이다. Reselect와 같은 라이브러리를 활용해보았지만 사실 나는 별다른걸 못 느꼈다.
오늘의 이슈
상품 목록을 불러오는 동안 네트워크 연결이 불안정한 상황에서 API 호출이 실패하는 문제가 발생했다.
→ Redux의 ‘fetchUser.rejected’ 케이스가 트리거되어 오류 메세지를 Redux 상태에 저장했다.’
앱이 서버로 api요청을 보내는 도중에 네트워크 연결이 불안정한 상황이 발생했다. API 호출이 실패하고 대신 오류 응답을 받게 되었다.
→ Redux의 ‘fetchUser.rejected’케이스 트리거: Redux를 사용하여 API 호출을 관리하고 있을 때, Redux Toolkit과 Redux Thunk 등을 활용하여 비동기 액션을 처리하는데, 호출이 실패하면 자동으로 ‘Rejected’케이스가 트리거된다. 이 경우, Redux에서 사용자가 정의한 ‘fetchUser’액션에 대한 ‘rejected’케이스가 실행된다
→’fetchUser.rejected’케이스에서는 API 호출 실패와 관련된 오류 메시지를 포함한 액션 객체가 생성된다. 이 오류 메시지는 Redux 상태에 저장되고, 일반적으로 Redux 상태에는 error 또는 errorMessage와 같은 필드가 있어 오류 메시지를 저장할 수 있다
👰🏻 사실 불안정한 네트워크 연결에 대한 해결책은 아니다. 길이 없는데 어떻게 가겠는가. 그냥, 오류 메시지를 어떻게 담을 것인지 확인했다.
사용자 인증 토큰이 만료되어 API 요청이 실패했다
→ 토큰 만료를 감지하고 리프레시 토큰을 사용하여 새로운 액세스 토큰을 얻어 API 요청을 재시도한다
→ 인증 토큰 만료에 대한 오류 핸들링을 통해 사용자에게 다시 로그인을 유도한다
이것도 Redux의 도움을 얻어보았다. fetchUser액션에서 토큰 만료 오류가 발생했을 때 리프레시 토큰을 사용하여 새로운 액세스 토큰을 얻는 과정이다
const fetchUser = createAsyncThunk('user/fetchUser', async (_, { dispatch, rejectWithValue }) => {
try {
const response = await fetch('/api/user', {
headers: {
Authorization: `Bearer ${accessToken}`,
},
});
const data = await response.json();
return data;
} catch (error) {
// 토큰 만료 오류인 경우 리프레시 토큰을 사용하여 재인증 시도
if (error.message === 'TokenExpiredError') {
try {
const newAccessToken = await dispatch(refreshToken());
// 새로 받은 액세스 토큰을 사용하여 다시 API 요청을 시도
const response = await fetch('/api/user', {
headers: {
Authorization: `Bearer ${newAccessToken}`,
},
});
const data = await response.json();
return data;
} catch (refreshError) {
// 리프레시 토큰으로도 재인증에 실패한 경우
return rejectWithValue('로그인이 필요합니다.'); // 오류 메시지 반환
}
}
return rejectWithValue(error.message);
}
});
서버에서 받은 데이터의 유효성을 검사하는 과정에서 실패했다
외부 데이터 소스에서 데이터를 가져와서 사용하는 중이였는데, 데이터 형식이 일치하지 않아 오류가 발생했다.
데이터 유효성 검사 오류 = 애플리케이션 서버로부터 받은 데이터가 예상과 다른 형식이거나 유효하지 않을 때 발생할 수 있는 어려움이다. → 데이터 형식 명확히 정의하기 : 서버와 클라이언트간에 통신할때 데이터의 형식을 명확히 정의해야 한다.
→ Joi /Yup 과 같은 유효성 검사 라이브러리를 사용한다 : 클라이언트 측에서는 Joi 나 Yup 같은 유효성 검사 라이브러리를 사용하여 데이터의 유효성을 간편하게 검사할 수 있다. 이러한 라이브러리를 활용하면 데이터 스키마를 정의하고 데이터를 검증하는 과정을 간소화할 수 있다
화면 전환시에 화면전환 애니를 사용자 정의하고 싶다면?
작업 중에 조금 밋밋했던 부분이 있었다. 리엑트 네이티브에서 화면 전환 애니메이션을 사용자 정의하는 것이 가능하고, ‘react-navigation’이라는 라이브러리를 활용하여 구현할 수 있다’
사용자 a와 사용자 b는 동시에 데이터베이스에서 동일한 사용자 정보를 가져와 수정하고 저장하려고 한다. 데이터베이스에는 사용자 a와 b가 동시에 업데이트를 시도하므로 충돌이 발생한다
충돌이 발생한 후 , 데이터베이스에서 최정적으로 저장된 사용자 정보를 마지막으로 업데이트해서 반영한다
충돌이 해결되는 과정
데이터베이스 업데이트
사용자 A와 사용자 B가 동시에 데이터베이스의 사용자 정보를 가져오고 수정합니다.
각각의 업데이트는 데이터베이스 트랜젝션 내에서 처리된다
데이터베이스 충돌 감지
데이터베이스는 사용자 A와 사용자 B의 업데이트가 동시에 실행되어 충돌이 발생했음을 감지한다
충돌 해결
충돌 해결에는 두가지 방법이 있다.
비관적 잠금 (Pessimistic Locking) : 사용자 A가 데이터를 가져올 때 데이터베이스에서 해당 데이터를 잠그고, 사용자 B는 데이터를 가져오는 동안 기다려야 한다. 이후 사용자 A와 B중 먼저 업데이트를 시도한 사용자의 변경 내용이 반영된다
낙관적 잠금(Optimistic Locking) : 사용자 A와 B가 데이터를 가져온 후 업데이트를 시도한다. 데이터베이스에서는 A와 B애가 가져온 데이터의 버전을 비교한다. 만약 버전이 동일하다면 업데이트를 허용하고 , 버전이 다르다면 충돌이 감지되었다고 알린다. 이후 A와 B에게 충돌을 해결하라고 선택권을 주거나, 나중에 다시 시도하도록 유도한다
최종 업데이트
충돌이 해결되고 데이터베이스에서 사용자 A와 B의 업데이트를 모두 반영한 후 , 최종 사용자 정보가 데이터베이스에 저장된다
이때, 마지막으로 업데이트한 사용자의 변경 내용이 반영되므로, 최종 나이가 32인 경우에는 사용자 B의 업데이트가 마지막으로 반영된 경우이다.
응답 및 결과
데이터베이스가 최종 업데이트를 수행한 후 , 사용자 A와 B에게 각각의 요청에 대한 응답을 반환합니다
응답은 수정 후의 최종 결과를 나타내며, 데이터베이스에서 저장된 최신 상태를 반영한다
이렇게 충돌이 발생하고 해결되면 최종적으로 데이터베이스에 반영된 결과를 사용자 A와 B에게 반환하여 제공된다. 충돌이 발생할 경우 충돌 해결 전까지 어느 한 사용자의 업데이트가 최종 반영되지 않은 것이다
오늘 하루 리뷰
정신없이 지나갔다. 원래는 아직 til 올릴 시간이 아니다. 야근을 많이 하니 til을 새벽에 올리곤 했다.
근데 오늘 몸이 너무 안따라준다. 헤롱헤롱한다. 너무 아프다. 진짜 두통이 너무 심하다. 글자를 읽을 때마다 울렁거린다. 약간 속도 메스껍고 토할 것 같다. 잠이 너무 온다. 죽을 것 같다 진짜. 속도 안좋다. 잠도 많이 온다. 어제부터 죽을 것 같아서 몬스터 흰색 캔을 2개를 땄다. 어쩌겠니... 돈벌어야 하는데...
몸이 너무 아프다. 잠이 너무 많아진다. 이러다가 진짜 죽는건 아닐지 하고 아픈데 열은 또 안 난다. 춥고 덥다. 근데 또 갑자기 미친듯이 먹고싶을때가 있다. 또 밥먹기 싫을때는 미친듯이 먹기 싫다.
프로젝트 개발하던 중에, 마이페이지 부분에서 무한 렌더링이 발생했다. 사용자가 페이지에 접속하면, 화면이 계속해서 새로고침되는 현상이 발생한 것이다.
무한 렌더링… 이노무시키를 해결하기 위해 React DevTools를 사용하여 컴포넌트 트리를 검사했다. 자꾸만 렌더링이 되는 컴포넌트를 확인했고, 해당 컴포넌트의 코드를 여러번 검토했다. 컴포넌트의 상태와 속성 또한 여러번 다시 봤는데도 잘 안 잡혔는데, 어휴 머리 아파 이러면서 물 뜨러 갔다가 찾아냈다!
해결책
1. 컴포넌트 상태 업데이트에 대한 조건 넣기
무한 렌더링이 발생한 컴포넌트 안에서 상태가 변경될때 조건문을 추가했다. 렌더링을 제어하기 위해서였다. 이렇게 두면 상태가 변경되지 않는 한 렌더링이 반복되지 않았다
class InfiniteRenderComponent extends React.Component {
state = {
count: 0,
};
componentDidMount() {
this.interval = setInterval(() => {
if (this.state.count < 5) { // 특정 조건을 만족할때만 렌더링하도록 쓴 코드
this.setState((prevState) => ({ count: prevState.count + 1 }));
}
}, 1000);
}
componentWillUnmount() {
clearInterval(this.interval);
}
render() {
return <div>{this.state.count}</div>;
}
}
나는 프로젝트에 문제가 생기면 , 인터넷과 공식문서를 미친듯이 뒤져서 답을 찾는다. 하지만 답을 그냥 그대로 붙여넣는 행동은 자제하자고 항상 생각한다.
내 뇌에 잘 녹아들어야지 내 코드에도 녹일 수 있다고 생각하기 때문이다. 그래서 항상 어떻게 사용해야 할 지 예시 파일을 만드는 편이다.
저 위의 파일도 그렇게 예시로 만들어본것이다.
2. . 컴포넌트 수명주기 메서드 활용 : ‘componentDidUpdate’
‘componentDidUpdate’ 라는 메서드를 사용해 상태 업데이트 후 렌더링을 조절할 수 있게 두었다.
메서드 이름이 …
👰🏻 컴포넌트는 업데이트 되었어요 !
너무 귀엽다 진짜… 메서드들 중 이름 귀여운거 진짜 많은데 와 나 진짜 왜 사람들이 이걸 몰라주지ㅠㅠ
3. 그래서 이게 무슨 원리인데?
주로 컴포넌트의 상태와 수명주기 메서드를 활용해 렌더링을 조절하고 무한 렌더링을 방지하는 것이다. 상태 업데이트 시에 특정 조건을 검사하거나 ‘componentDidUpdate’메서드를 활용하여 필요한 경우 렌더링을 제어한다. 이러한 방식으로 React 컴포넌트에서 발생하는 무한렌더링 문제를 해결할 수 있다.
렌더링이 문제다 문제.
대규모 데이터를 다루는 React 애플리케이션일수록 화면이 느리게 렌더링된다. 이는 정말 당연한 이야기이다. 당연하지. 처리해야 할 게 많으니 느려지는 거는.
그런데,,,
👿 컴포넌트가 불필요하게 재랜더링되는거는 그냥 신경을 안 쓴 거잖아!
아니, 내가 왜 이렇게 코드를 짰을까 두번 세번 후회하면서 다시 또 DevTools를 꺼내들었다.
어. 정말 답이 없었다.
DevTools 사용: React Developer Tools의 Profiler 탭을 사용하여 리렌더링을 초래하는 원인을 추적했다.
코드 리뷰: 해당 컴포넌트의 props와 state의 변화를 주의 깊게 살펴보았다.
아마 문제의 원인은 부모 컴포넌트에서 불필요하게 자식 컴포넌트에게 전달되는 props 때문이었다.
React.memo 사용 : 동일한 props와 state로 호출될 때 재렌더링을 방지하는 역할을 한다
컴포넌트 분리 : 불필요한 리렌더링을 초래하는 props를 가진 부분을 독립된 컴포넌트로 분리하기
1. Memoization 라이브러리
Memoization 라이브러리란?
→ 함수 결과를 캐싱하고, 동일한 인자로 함수를 호출할 때 캐싱된 결과를 반환하는 방법을 고려했다
해결책
Memoization 라이브러리 중하나인 ‘memoize-one’을도입하여 컴포넌트의 최적화를 진행해보았다. 이 라이브러리를 사용하면 함수의 결과를 메모이제이션하여 동일한 인자로 함수를 호출할 때 불필요한 연산을 피할 수 있다. 그러니까… 컴포넌트의 렌더링 . 효율적으로 관리되겠죠?
이게 왜 되는거냐면 Memoiization은 함수 호출 결과를 캐싱하여 이전에 계산한 값을 재사용했다. 이로서 연산의 중복을 방지했지롱. 저 라이브러리 리엑트 컴포넌트에서 쓰기 짱 편한듯
import memoize from 'memoize-one';
// Memoization 함수 생성
const memoizedFunction = memoize((arg1, arg2) => {
// 복잡한 계산 로직
return arg1 + arg2;
});
// 컴포넌트 내에서 Memoization 함수 사용
const result = memoizedFunction(5, 10); // 이후 동일한 인자로 호출 시 캐시된 결과 반환
왜 얘는 막쓴 코드 없냐고 물어볼 것 같아서 들고왔다.
함수의 결과가 캐싱되어 동일한 인자로 호출될때까지 계산되지 않고 캐싱된 결과가 반환된다. 이로 컴포넌트의 렌더링을 최적화할수 있다.
2. React.memo
리엑트의 성능 최적화 기능 중 하나다. PureComponent 이랑 유사한 기능을 함수형 컴포넌트에서도 사용할 수 있단다…오
→ 아침에 의외로 일찍 일어났다. 요즘 수면패턴이 다시 돌아오는 것인가? 안 꺠웠는데도 일어나고 난리다. 하루만이라도 정상적인 수면 패턴을 가지면 좋겠다는 염원을 품고 산지가 몇 년째인데 드디어 푹 잤다. 너무 행복했다.
→ 키보드 스테빌이 너무 찰찰거린다. 슬슬 공방에 맡겨야 할 때가 온 것 같다.
→ 내가 언제부터 이렇게 키보드 덕후가 되었을까?
🌩 WORK TIME
오늘 시간을 못 재었지만 적어도 8시간은 넘게 집중한 것 같다.
🌩 WHAT I DID
본강의를 수강하며 필기했다
팀원들을 위해 쉽게 JARM을 이해할 수 있도록 가이드를 만들었다
Jarm 실습을 하였다
모르는 용어들을 한꺼번에 정리했다
리눅스 사용법을 공부했다
→ 보안을 공부하며 굳이 굳이 굳이 왜 리 눅스를 쓰는지는 모르겠지만 말이다.
🌩 WHAT I LEARNED
🦉 소켓 프로그래밍
보안 프로그래밍에서 ‘프로그래밍’은 환경을 구성하는 것이 매우 중요하다
💡 소켓 프로그래밍에 대한 기본적인 개념을 바탕으로 실제로 구현하는 부분들에 대한 코드를 독자적으로 구현할 수 있는 시간을 가져보아야 할 것 같다 !
파이썬 언어를 사용해서 실습을 진행할 거기 때문에 파이썬이 설치가 돼 있어야 한다
🦉 파이썬 부터 어떻게 해보쇼 …
파이썬을 실행하는 다양한 방식이 있는데 크게는 두 가지 방식이 있다
첫 번째는 vs 코드를 열어서 터미널을 눌러주면 터미널 창이 뜬다
터미널을 눌러주면 터미널 창이 뜨고 거기서 파이썬을 실행할 수 있다. 만약 당신이 우리 5조가 아니지만 우연한 기회에 이 블로그를 보신 분이라면, VSCODE 기본 세팅법은 인터넷에 널리고 널렸으니 가서 찾아보시는 걸 추천한다. 우리 조원이라면, 슬랙 보내세요. 저 칼답임
🦉 소켓 프로그래밍의 배경
소켓 프로그래밍은 컴퓨터 네트워크를 통해 서로 통신하는 애플리케이션을 개발하기 위한 프로그래밍 기술이다.
강사님은 소켓 프로그래밍을 설명하기 전에, 소켓 프로그래밍을 처음 접할 때 흥미로운 배경이 있다고 하셨다. 예전에 프로그래밍을 하면서 로컬 PC에서 테트리스 게임을 만들어 본 적이 있는데, 예제를 보고 따라 만들어 봤다고 하셨다.. 그러던 중에, 이런 궁금증이 들었습니다. "테트리스 게임은 지금 나 혼자서 플레이를 하지만 원격에 떨어져 있는 다른 사람들이랑 같이 플레이를 하려면 프로그래밍으로 어떻게 해야 될까?" 그래서 그 방법을 알아보니, 소켓 프로그래밍 이라는 도구를 통해 "가능하다"는 것을 알게 돠셨다고 한다.
소켓 프로그래밍은 서로 통신하려는 의사가 있을 때 이루어지며, 가장 중요한 것은 약속이다
💡 약속을 영어로는 "프로토콜"이라고 합니다. 보안 공부를 하면서 이 말을 자주 들을 것이다
서로 떨어져 있는 사람들이 대화를 나누거나 통신을 할 때, 약속된 형태로 데이터를 주고받아야 한다. 서로 무슨 얘기를 하는지, 문제는 없는지, 그리고 내가 보내는 메시지는 어디에 담겨야 하는지 등이 가장 중요한 약속이다.
🦉 소켓 프로그래밍의 기본
소켓 프로그래밍을 할 때, 데이터를 보낼 때는 데이터 형태를 보내기로 약속한 값들 양식에 일일이 하나하나 다 채워서 보내야 한다
이를 직렬화라고 한다.
<aside> 💡 네트워크나 파일 시스템은 일반적으로 데이터를 연속된 바이트 단위로 다루기 때문에, 데이터를 전송하거나 저장하기 위해서는 그 데이터를 일련의 바이트로 변환하여야 한다. 이렇게 변환된 데이터를 직렬 데이터라고 부른다
</aside>
→ 직렬화를 할 때, 데이터를 보내기로 약속한 값들을 하나하나 다 채워서 보내는 이유는 데이터의 구조와 의미를 보존하기 위해서이다. 보내는 측과 받는 측 사이에 공통된 데이터 구조에 대한 약속이 있어야 정확한 데이터 교환이 가능하다. 정수, 문자열, 부동소수점 숫자 등을 어떤 형식으로 표현하고 어떤 순서로 나열할 것인지에 대한 규칙이 필요하다.
→ 아, 웹 애플리케이션에서 클라이언트와 서버 간에 데이터를 주고받을때도 데이터를 직렬화하여 전송ㄹ한다. 대부분의 웹 서비스에는 JSON이나 XML같은 형식으로 데이터를 직렬화여 전송한다
→ 분산 시스템에도 쓰인다. 분산 시스템 환경에서 여러 컴퓨터나 서비스 간에 데이터를 주고받을 떄, 데이터를 직렬화하여 전송하면 효율적으로 데이터를 교환할 수 있다 .
일반적으로는 구조체나 클래스의 필드를 바이트로 변환하고, 그 바이트를 네트워크를 통해 전송하거나 파일에 저장한다. 수신 측에서는 이를 반대로 진행하여 바이트를 원래의 데이터 형태로 역직렬화 한다. 직렬화와 역직렬화를 통해 데이터의 구조와 의미를 보존하면서 네트워크 상에서 데이터를 교환하거나 파일에 저장할 수 있게 된다.
🦉 데이터 직렬화의 전송/저장 과정
데이터 직렬화
구조체나 클래스의 필드를 순서대로 읽어와 이를 바이트로 변환한다.
→ 일반적으로 프로그래밍 언어나 직렬화 라이브러리가 이를 담한다
각 필드의 데이터를 특정 규칙에 따라 바이트로 표현한다
이렇게 생성된 바이트들은 데이터의 구조와 의미를 보존하면서 하나의 연속된 데이터 시퀀스로 만들어진다
💁♀️ 이 규칙은 프로그래밍 언어나 직렬화 라이브러리들마다 다를 수 있다
네트워크를 통한 전송
직렬화된 바이트는 네트워크를 통해 전송된다.
네트워크 프로토콜은 이전 데이터를 송수신하는 규칙을 정의한다
송신 측에서는 직렬화된 데이터를 네트워크로 보내고, 수신 측에서는 네트워크로부터 데이터를 받아들인다.
파일에 저장
직렬화된 데이터는 파일에도 저장할 수 있다. 파일에 저장하는 방법은 데이터를 네트워크 통해 전송하는 것과 유사하다.
직렬화된 데이터를 파일에 쓰고 나중에 읽어와 역직렬화하면 원래의 데이터 구조와 의미를 복원할 수 있다.
💡 예를 들어, Java의 경우 Java Serialization API나 JSON 라이브러리를 사용하여 직렬화와 역직렬화를 수행할 수 있다. Python의 경우 pickle 모듈을 사용하여 직렬화와 역직렬화를 할 수 있다. C++에서는 std::ostream 및 **std::istream**을 사용하여 데이터를 직렬화하고 역직렬화할 수 있다.
🦉 용어 정리 타임
구조체 (struct)
프로그래밍 언어에서 데이터와 해당 데이터에 대한 메서드를 결합한 자료구조를 생성하기 위해 사용
이들은 Field 라고 불리는 변수들의 집합을 포함하며 데이터를 더 의미 있는 단위로 묶을 수 있게 함.
구조체는 주로 c, c++, rust 등에서 많이 사용되기에 님이 잘 안 들어봤을 가능성이 크다
클래스는 객체 지향 프로그래밍 언어인 java, c#, python 등에서 사용된다.
필드 (Field)
필드는 구조체나 클래스 내부에서 데이터를 저장하는 변수를 말한다
예를 들어, 사용자 정보를 저장하는 구조체에는 이름, 나이, 이메일 주소 등이 필드가 될 수 있다.
구글 설문조사 할 때 ‘필드가 다 채워지지 않았습니다 ‘ 멘트의 그 필드 맞다
🦉 근데 ! 소켓 라이브러리를 이용하면 쉽게 채울 수 있음
메시지 하나, 아니 패킷 하나를 보낼 때마다 ip addr, destinatiopn ip adr 등 많은 것을 채워서 보내야 하 는데, 이걸 다 어떻게 채우냐. 아무렇게나 채우면 되는 게 아니고 여기 표준 문서 보고 표준 문서에 맞게 일일이 패킷 하나하나 보낼 때마다 전부 주소랑 목적지 채우고 옵션이랑 플래그값 다 채워야 하기 때문에 상당히 귀찮다.
👨🔧 그럼 지금은 어떻게 보내고 있는데?
🙋🏻♀️ 소켓 라이브러리로 보내지?
저렇게 귀찮게 하나하나 채워 보내야 하는 것을 자동으로 채워서 보내주는 라이브러리가 있다.
우리는 이것을 소켓 라이브러리라고 부른다. 우리가 서로 사전에 데이터를 주고받을 떄 필요한 ip라는 녀석을 데이터를 일일이 하나하나 다 채우지 않고도 아주 쉽고 간단히 지 알아서 채워준다.
💡 소스 ip, addr 그다음에 데스티네이션, ip, 주소, 어드레스 ← 우리가 원하는 것
우리는 이거에 제일 관심이 있기 때문에 요것만 채우면은 나머지들은 약속된 형태로 자동으로 채울 수 있게끔 도와준다.
이것이 바로 소켓 프로그래밍이다 !
🦉 TCP 데이터 구조 및 소켓 프로그래밍
TCP 프로토콜은 신뢰성 있는 데이터 전송을 보장하기 위한 프로토콜(약속)이다.
이 또한 데이터의 구조와 전송 과정이 중요한 역할을 합니다. 이를 자세히 알아보겠다.
🦉 TCP 데이터 구조
TCP 데이터 구조는 데이터의 무결성을 유지하고 재전송 기능을 지원하기 위해 다양한 데이터 필드를 포함한다.
💡 예를 들어, 데이터 전송 시 데이터에 해시 값을 첨부하여 데이터의 무결성을 검증할 수 있습니다. 이렇게 체크섬이나 해시 값은 데이터가 손상되지 않았는지 확인하며, 손상된 경우 재전송을 통해 데이터의 완전성을 보장할 수 있다.
🦉 TCP의 포트
TCP의 포트는 통신하는 프로세스를 식별하기 위한 주소 역할을 한다.
서로 다른 포트를 사용함으로써 여러 서비스가 동시에 운영될 수 있고, 충돌을 방지할 수 있다.
💡 예를 들어, 웹 서비스는 주로 80번 포트를 사용하며, 이메일 서비스는 25번 포트를 사용한다
포트에는 다양한 서비스가 할당되며, 이는 서비스와 관련된 포트 번호를 사용하여 데이터 흐름을 식별한다
예상 질문 : 충돌나는 포트는 도대체 어디서 돌아가고 있는 것인가?
어플리케이션마다 기본적으로 사용하는 포트가 있음
HTTP (80번 포트)
HTTPS (443번 포트)
FTP (20번 포트 및 21번 포트).
SSH (22번 포트)
SMTP (25번 포트)
POP3 (110번 포트)
IMAP (143번 포트)
DNS (53번 포트)
특정 포트가 어디서 사용되는지 확인하는 방법은?
lsof -i : (포트번호)
추가 질문 : 맥 os에서 5000번은 왜 작동하지 않는가?
stackoverflow들을 참고하니 airplay에 할당된 포트이기에 5000번 포트에 할당되어 있다는 답변을 볼 수 있었다.
그러나 airplay 수신 모드를 해제했음에도 작동하지 않았다
애플 공식 사이트를 참고하니 5000번에 할당된 것은 upnp라고 한다
Universal Plug And Play
홈 네트워크에서 장치 이름을 찾는 (bonjour/rendezvous)가 작동하는 방식인 멀티캐스트 dns가 할당되어 있다고 한다.
🦉 로우 스택 프로그래밍
로우 스택 프로그래밍은 네트워크 스택의 낮은 수준 기능을 직접 다루는 프로그래밍 방식이다. 소켓 라이브러리를 사용하지 않고, 패킷을 직접 조작하고 데이터를 송수신할 수 있다. 하지만 보안 문제와 비효율성으로 인해 실제 업무에서는 자주 사용되지 않는다.
🦉 통신 절차
TCP 통신 절차는 초기 연결 설정부터 데이터 전송, 연결 종료까지의 과정을 나타냅니다. 초기에는 "Three-way handshake"를 통해 세션을 설정하며, 데이터 전송 과정과 연결 종료 과정은 순차적인 단계를 거칩니다. 통신 과정에서 각 단계별로 상태 정보와 플래그를 사용하여 신뢰성 있는 통신을 보장합니다.
🌙 Three-way handshake
TCP 통신을 시작하기 위해 클라이언트와 서버 간에 세션을 설정하는 과정이다.
이 과정은 클라이언트와 서버 사이에서 상호적인 신호를 주고받아 서로가 통신에 준비되었음을 확인하는 과정으로, TCP 연결의 안정성과 신뢰성을 보장하기 위해 중요하다.
👨🔧 안녕하세요, 저 곧 저기로 전화 걸 건데요!
🙋🏻♀️ 아 그러시구나 . 처음 만나뵈어서 반갑습니당
👨🔧 전화 받을 준비 되셨나요??
🙋🏻♀️ 넹 !
THREE-WAY HANDSHAKE 과정
클라이언트가 서버에게 요청 (SYN)
클라이언트는 서버에게 통신을 시작하려는 의도를 전달하기 위해 SYN(동기화 요청) 플래그를 설정한 패킷을 전송한다
💡 이 패킷에는 클라이언트의 초기 순차 번호(Sequence Number)도 포함되어 있다.. 이 순차 번호는 데이터의 순서를 식별하는 역할을 한다
서버가 응답 (SYN + ACK)
서버는 클라이언트의 요청을 받고, 통신을 수락하려는 의사를 표시하기 위해 SYN 플래그와 ACK(확인 응답) 플래그를 모두 설정한 패킷을 전송한다
💡 이 패킷에는 서버의 초기 순차 번호와 클라이언트로부터 받은 순차 번호에 1을 더한 값을 포함힌다. 이는 서버가 클라이언트의 데이터를 기다리는 상태임을 나타낸다
클라이언트가 응답 확인 (ACK)
클라이언트는 서버의 응답을 받고, 통신이 성립되었다는 것을 확인하기 위해 ACK 플래그를 설정한 패킷을 전송한다
이 패킷에는 서버로부터 받은 초기 순차 번호에 1을 더한 값을 포함한다 이제 클라이언트와 서버 간의 연결이 성립되었디.
TCP 데이터 구조체
TCP 데이터 구조체는 TCP 연결 세션 내에서 클라이언트와 서버 간의 상태 정보를 담고 있는 녀석이다 . 이 구조체는 소켓 정보, 시퀀스 넘버, 윈도우 크기 등을 포함하며, 패킷의 전송과 관련된 중요한 정보를 제공한다.
공통점
ㅤ
공통점
네비게이션
지도와 방향을 제공하여 목적지에 도달할 수 있게 해줌
tcp 데이터 구조체
데이터의 방향과 순서를 제어하여 효율적인 데이터 통신을 가능하게 만든다
👨🔧 엥? 이거 네비게이션 같은 거야?
🙋🏻♀️ 비슷하게 이해하면 쉬워! 차이점이라고는 네비게이션은 실제 공간의 길을 안내하는데, tcp 데이터 구조체는 데이터 패킷의 방향과 순서를 관리하는 거 정도>?
👨🔧 아하 ! 그럼 신호등 정도면 비유가 될 것 같아!
🙋🏻♀️ 신호등이랑도 비슷하네. 데이터 손상과 순서 무너짐을 방지하고 재전송시키기도 하니깐.
네비게이션
지도와 방향을 제공하여 목적지에 도달할 수 있게 해줌
tcp 데이터 구조체
데이터의 방향과 순서를 제어하여 효율적인 데이터 통신을 가능하게 만든다
👨🔧 엥? 이거 네비게이션 같은 거야?
TCP 데이터 구조체에는 뭐가 들어 있는데 ?
소켓 정보: TCP 데이터 구조체에는 통신을 위해 생성된 소켓의 정보가 포함된다.
이 정보는 클라이언트와 서버가 통신하기 위한 인터페이스 역할을 한다
시퀀스 넘버: 시퀀스 넘버는 TCP 연결 세션에서 전송되는 데이터의 순서를 관리하는 데 사용됩니다.
데이터 패킷의 순서를 유지하기 위해 시퀀스 넘버가 할당되며, 수신측에서는 이를 통해 정확한 순서로 데이터를 재조립할 수 있다.
윈도우 크기: 윈도우 크기는 한 번에 전송할 수 있는 데이터의 양을 나타낸다.
이 크기는 데이터의 흐름을 관리하고 효율적인 전송을 위해 조절됩니다. 수신 측은 윈도우 크기를 통해 송신 측에게 받을 수 있는 데이터 양을 알려주며, 이를 기반으로 데이터를 조절한다
종단 정보: TCP 데이터 구조체는 통신 종단점인 클라이언트와 서버의 정보를 포함한다</aside>
이를 통해 데이터를 올바른 대상에게 전송하고 수신할 수 있다
💡 종단이란? 네트워크 통신에서 데이터의 출발지 또는 목적지를 나타내는 개념. 즉, 네트워크에[서 데이터가 시작되는 곳 또는 도착하는 곳을 의미한다 . 일반적으로 네트워크에서 호스트를 식별하는 주소를 나타낸다. 이 주소는 IP주소와 포트 번호의 조합으로 이루어져 있다. IP주소는 호스트를 네트워크에서 고유하게 식별하는 역할을 하고, 포트 번호는 해당 호스트 내에서 어떤 프로세스나 서비스와 통신할지 나타낸다.
플래그와 제어 정보: TCP 데이터 구조체에는 통신의 상태와 제어 정보를 나타내는 플래그가 포함된다.
이러한 플래그는 데이터 전송의 성공 여부, 에러 여부 등을 나타내며, 효과적인 통신을 위해 사용된다
💡 예를 들어 웹 브라우저가 웹 서버에 데이터를 요청할 떄, 브라우저는 웹 서버의 IP주소와 웹 서버가 제공하는 웹 서비스의 포트 번호를 사용하여 해당 웹 서버의 종단점에 연결한다. 이를 통해 데이터는 웹 서버로 전송되어 웹 페이지를 요청하고 응답을 받을 수 있다.
소켓 프로그래밍의 개념
소켓 프로그래밍은 TCP 데이터를 주고받기 위한 인터페이스를 제공한다.
데이터를 받을 때 : 소켓을 생성하고recv()함수를 사용하여 데이터를 읽어옴 .
데이터를 보낼 때 : 소켓을 생성하고send()함수를 사용하여 데이터를 전송함
이를 통해 송수신자 간에 신뢰성 있는 데이터 통신을 구현할 수 있다
과제
💡 과제 1번
실습 1 : echo 서버/클라이언트 목표: 클라이언트로 부터 TCP/IP 접속을 대기하고 클라이언트 수신 데이터를 그대로 전송(반환)하는 서버 프로그램 작성 상세조건 :
서버는 127.0.0.1 or localhost 를 IP주소를 사용한다. 서버가 사용하는 포트는 8080이다. 클라이언트로 수신한 데이터를 화면에 그대로 출력하고 내용 그대로를 전송(반환)한다.
그냥 평범하게 하기에는 성에 안 차서 공주님 컨셉 잡고 코드 작성했다.
하녀가 공주님을 —에서 기다리고 있습니다…?
진짜 무슨 중세풍 공주냐고요.
클라이언트 코드
import socket
HOST = '127.0.0.1'
PORT = 8089
server_socket = socket.socket(socket.AF_INET, socket.SOCK_STREAM)
server_socket.bind((HOST, PORT))
server_socket.listen()
print(f"하녀가 공주님을 {HOST}:{PORT} 에서 기다리고 있습니다.")
while True:
client_socket, addr = server_socket.accept()
print(f"공주님이 {addr} 에서 찾아오셨습니다.")
data = client_socket.recv(1024)
received_data = data.decode('utf-8')
print(f"공주님이 보내신 메시지: {received_data}")
client_socket.sendall(data)
print("공주님께 메시지를 전달했습니다.")
client_socket.close()
물론, 공주님. 해당 코드는 Python에서 소켓 프로그래밍을 이용하여 간단한 클라이언트-서버 통신을 구현한 예제입니다. 이 예제는 서버 측에서 클라이언트의 연결을 받아들이고, 클라이언트로부터 메시지를 받아 그대로 다시 보내주는 간단한 에코 서버를 만드는 것을 목표로 하고 있습니다. 이제 코드를 조금 더 자세히 살펴보겠습니다.
import socket: Python의socket모듈을 불러옵니다. 이 모듈은 네트워크 통신을 다룰 수 있도록 도와주는 기능들을 제공합니다.
**HOST = '127.0.0.1'**과PORT = 8089: 서버의 IP 주소와 포트 번호를 설정합니다. 현재 설정은 로컬 머신에서 테스트하기 위한 것으로, 127.0.0.1은 자기 자신을 가리키는 IP 주소입니다.
server_socket = socket.socket(socket.AF_INET, socket.SOCK_STREAM): 서버 소켓을 생성합니다. **AF_INET**은 IPv4 주소 체계를 사용하겠다는 것을 의미하고, **SOCK_STREAM**은 TCP 소켓을 사용하겠다는 것을 의미합니다.
server_socket.bind((HOST, PORT)): 서버 소켓을 특정 IP 주소와 포트 번호에 바인딩합니다.
server_socket.listen(): 클라이언트의 연결 요청을 기다리기 위해 서버 소켓을 리스닝 상태로 만듭니다.
print(f"하녀가 공주님을 {HOST}:{PORT} 에서 기다리고 있습니다."): 서버가 시작되었음을 알리는 메시지를 출력합니다.
while True:: 무한 루프를 시작하여 클라이언트의 연결을 계속해서 받아들일 수 있도록 합니다.
client_socket, addr = server_socket.accept(): 클라이언트의 연결 요청이 들어오면, 해당 클라이언트와의 소켓 연결을 생성합니다. **accept()**는 연결 요청을 수락하고 클라이언트 소켓과 주소 정보를 반환합니다.
data = client_socket.recv(1024): 클라이언트로부터 최대 1024바이트까지의 데이터를 받을 수 있어요.
received_data = data.decode('utf-8'): 받은 데이터를 UTF-8 인코딩을 사용하여 문자열로 디코딩 할 거예요.
client_socket.sendall(data): 클라이언트에게 받은 데이터를 그대로 보내줍니다. 이렇게 하면 클라이언트에게 데이터가 에코되어 돌아갑니다.
client_socket.close(): 클라이언트와의 연결을 닫죠.
서버 코드
import socket
HOST = '127.0.0.1'
PORT = 8099
server_socket = socket.socket(socket.AF_INET, socket.SOCK_STREAM)
server_socket.bind((HOST, PORT))
server_socket.listen()
print(f"서버가 공주님을 {HOST}:{PORT} 에서 기다리고 있습니다.")
while True :
client_socket, addr = server_socket.accpet()
print(f"공주님이 {addr} 에서 찾아오셨습니다.")
data = client_socket.recv(1024)
received_data= data.decode('utf-8')
print(f"공주님이 보내신 메시지: {received_data}")
client_socket.sendall(data)
print("공주님께 메시지를 전달했습니다.")
client_socket.close()
공주님 컨셉 최고야 !!
Jarm Generator 실습
jarm(just another resource Negotiator)은 SSL/TLS 핸드셰이크 패킷을 분석하여 네트워크 서비스나 애플리케이션을 식별하는데 사용되는 도구이다.
SSL/TLS 핸드셰이크는 서버와 클라이언트 간의 보안 연결을 설정하기 위한 초기 단게로, 이 단계에서 사용되는 핸드셰이크 값들은 서버나 애플리케이션의 특징을 나타내는 경우가 많다.
Jarm은 이러한 핸드셰이크 값들을 분석하여 고유한 식별자를 생성하며, 이를 통해 서비스를 식별할 수 있다.
💡 웹서버, vpn 서비스. 메일 서버 등 서비스가 다르면 홴드셰이크 값에서 나타나는 특징들이 다를 수 있기 때문이다.
→ 보안 전문가가 어떤 환경에서 어떤 서비스가 실행 중인지 더 정확하게 판단하도록 도와 적절한 보안 조치를 취할 수 있도록 도와준다.
→ 네트워크 분석, 보안 조사, 침투 테스트 등 다양한 상황에서 유용하게 활용될 수 있다.
🙎♀️ 그러니까, 내가 웹서버로 접근하고, 네가 메일 서버로 접근한다면?
👨🔧 우리의 핸드셰이크 값은 다를테니 누가 누군지 얘가 알려주겠지!
💁♀️ 그럼 이 실습은 뭐 하는 건데???
Jarm의 특징
한 그룹의 모든 서버가 동일한 TLS 구성을 갖는지 빠르게 확인한ㄷ.
다양한 서버를 구성별로 그룹화하여 Google, Salesforce, Apple과 같은 조직을 식별한다.
기본 응용 프로그램이나 인프라를 식별한다.
악성 소프트웨어 명령 및 제어 인프라와 같은 악성 서버를 식별한다.
Python으로 작성되었다.
jarm generator
이 프로그램을 사용하여 특정 도메인 또는 IP 주소에 대한 jarm 핸드셰이크 값을 생성할 수 있다.
설치부터 해보자고 !
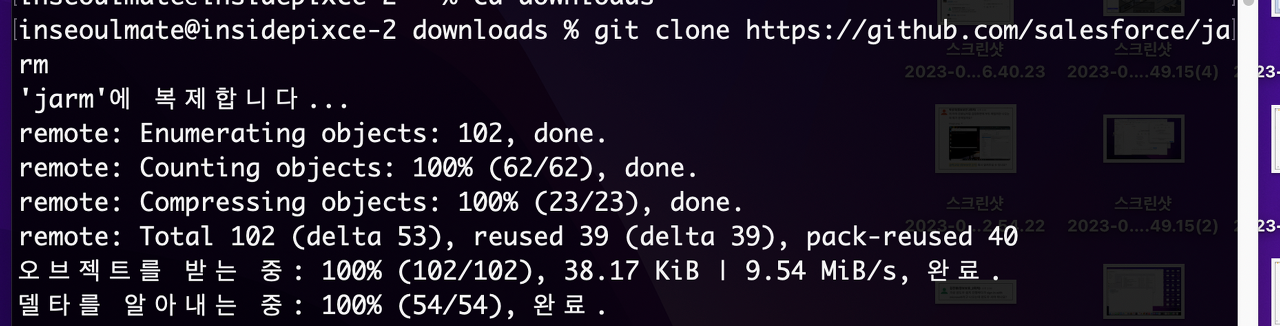
git clone <https://github.com/salesforce/jarm>
깃허브에 올라와있는 jarm 파일을 클론해준다
그러면 이렇게 하나하나 다운받아진다
cd downloads
cd jarm
경로에 맞춰서 들어가준다.
근데 뭐, 본인이 원래 폴더에 깔았다면 cd jarm만 해줘도 된다.
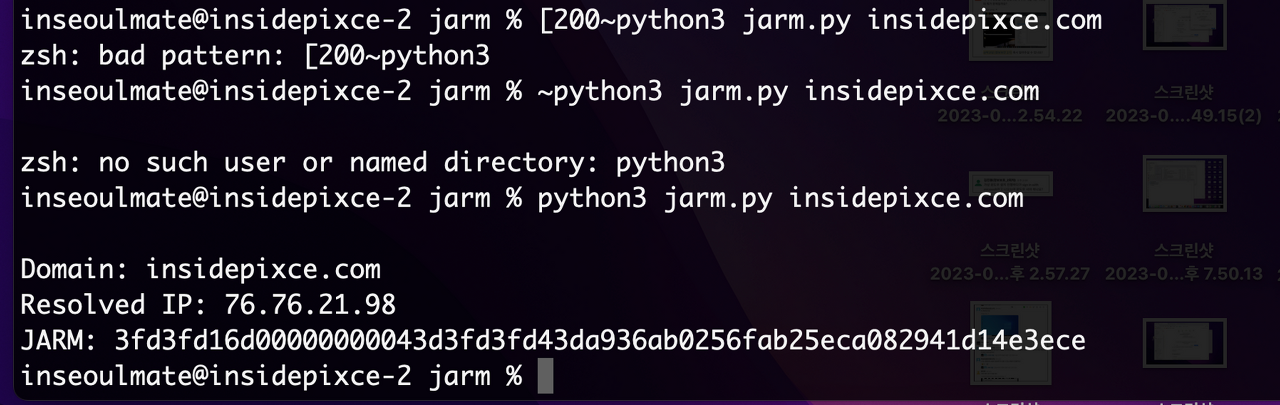
실습해보았다
나의 블로그인 insidepixce.com으로 10개의 TLS 헬로 패킷을 대상 TLS서버로 보내고, 해당 서버의 헬로 응답의 특정 속성을 캡처하여 동작한다.
이를 통해 얻은 TLS 서버 응답을 특정 방식으로 해시하여 JARM 핑거프린트를 생성한다.
이 때 클라이언트 헬로는 서로 다른 TLS 버전, 암호화 방식, 확장 등을 다양한 순서로 보내면서 고유한 응답을 얻는 것이다.
그럼 이거 어떻게 읽어?
JARM 핑거프린트는 특정 방식으로 해시된 퍼지 해시(fuzzy hash)로, 암호화와 관련된 보안 기능이 아니다. 이 해시는 기계뿐만 아니라 사람도 읽을 수 있도록 디자인되었다.
첫 30자는 10개의 클라이언트 헬로 중 서버가 선택한 암호화 및 TLS 버전으로 이루어져 있음
“000”은 해당 클라이언트 헬로한테 요청 날렸는데 안 준 경우를 나타낸다
나머지 32자는 서버가 보낸 확장의 누적을 sha256 해시한 값이다.
JARM 핑거프린트를 비교할 때, 마지막 32자가 다르지만 첫 30자가 다르면 서버가 매우 유사한 구성을 가지고 있다고 한다.
자바스크립트가 발전하며 , AJAX (비동기 통신) 형태로 서버와 통신을 주고받는 사이트가 많아졌고, 새로고침 없이 데이터를 가져오게 되었다. 자바스크립트가 동적으로 만든 데이터를 크롤링할때, 그리고 사이트의 다양한 HTML요소에 클릭, 키보드 입력 등 추가 이벤트를 주기 위해 Selenium을 사용한다.
셀레니움 기본 세팅을 해준다
from selenium import webdriver
from selenium.webdriver.chrome.service import Service
from selenium.webdriver.chrome.options import Options
셀레니움의 웹드라이버, 크롬 서비스, 옵션들을 가지고 와준다
from selenium.webdriver.chrome.service import Service
크롬 웹 브라우저를 실행하기 위한 WebDriver 서비스를 설정한다.
이는 실제 브라우저 인스턴스를 관리하고 제어한다
selenium.webdriver.chrome.options import Options
크롬 브라우저를 실행할 때 설정 옵션을 관리하기 위한 클래스 Options를 가져온다. 브라우저 동작을 커스터마이즈 할 수 있는 다양한 설정을 포함한다. 브라우저 창 크기, 브라우저 창 숨기기 등의 설정을 제어할 수 있다.
selenium을 사용하여 자동화하는 과정에서 필요한 초기 설정을 모두 마쳤으면, 뒤로 가보자
브라우저 종료 현상 방지
셀레니움 동작이 스레드를 통해 브라우저를 켜는 방식이라 프로세스가 종료되면 스레드가 종료되는데, 이걸 막기 위해서 브라우저 종료를 방지해주는 코드를 작성한다
driver.find_element(By.CSS_SELECTOR, "#id") 를 통해 ID 입력창을 찾고, 입력창을 클릭해준다.
근데 … 여기서 파이퍼클립이 안 먹었다 ! 아니 세상에…
그래서 방향을 틀었다.
스택오버플로우 선생님들 ! 제게 힘을 주세요 !!!!!!
🙋🏻♀️ CAPCHA 우회하는 거 불법인가요? 불법 아니면 어케 뚧나요?
💁🏻 우회하는 거 불법 맞음 ㅇㅇ 2capcha 사용하면 우회 가능. 결제하면 우회 가능함 ㅇㅇ
하. 캡챠 우회가 불법이였다니. 그러면 일단 자동으로 비밀번호와 아이디가 입력된다는 기능에 초점을 두자!! 는 방향으로 코드를 써보기 시작했다.
좀 더 깔끔하게 ! 좀 더 가독성이 높게 ! 좀 더 확실하게 !
⌨️ 뒤집어 엎자! 코드!
불러올 것들
from selenium.webdriver import Chrome, ChromeOptions, Keys
from selenium.webdriver.chrome.service import Service
from webdriver_manager.chrome import ChromeDriverManager
from selenium.webdriver.common.by import By
from selenium.webdriver.support import expected_conditions as EC
from selenium.webdriver.support.wait import WebDriverWait
import time
--start-maximized : 크롬 브라우저 실행할 때 창을 최대화하여 연다. 전체화면이라고 생각하면 편하다. 원래 이거 설정 안 해주면 창 모드로 뜬다 ;;
add_experimental_option("excludeSwitches", ["enable-automation"] : 원래는 크롬 브라우저 자동화 감지해서 컷한다. 셀레니움을 사용할때 일부 웹사이트에서 자동화를 감지해서 접금제한 때릴 떄가 있는데… 이 옵션 켜서 막을 수 있다.
wait = WebDriverWait(driver, 10)로 최대 10초를 가디려준다. 웹이 로딩될때까지 기다려준다. 우리가 가져올 요소들이 바로 안 나타날때 쓴다.
그럼 driver.implicitly_wait(5) 이건 뭐냐?
implicitly_wait을 사용하여 일반적인 요소 찾기에 대한 대기 시간을 갖고, **WebDriverWait**를 사용하여 특정 조건을 충족할 때까지 대기한다. 복잡하다. 전자는 대기하는 객체를 ‘생성' 하는거고. 후자는 대기하는 암묵적 대기 시간을 ‘설정’한다의 차이가 있다. 후자로 동적으로 로딩되는 경우를 처리하고 완전히 로딩 안 되어도 바로바로 쓸 수 있게 된다.
→하나만 써도 되는데, implicitly_wait만 쓸 경우 모든 요소에 똑같은 대기 시간이 적용되었다 ! 어떤게 로딩 안 된 경우에는 너무 오래 걸렸다.
웹 페이지가 로드될 때까지 기다렸다가 비밀번호 입력창을 찾아 비밀번호를 입력한다. 이후 10초 동안 기다린다.
뭔 대기가 이렇게 많아… 하는데 다 로드되었는지 확인하고 확인하고 확인하고 또 확인하는 과정이다.
엔터키 누르고 로그인 폼 submit 하기
password.send_keys(Keys.ENTER)
input()
원래는 로그인 버튼을 클릭하려고 했는데 엔터가 더 효율이 좋은 것 같았다 ;
저놈의 input()을 꼭 써줘야 페이지가 바로 안 닫힌다. 성빈이(바보멍청이흰둥이)가 먼저 공부했던 내용이여서 바로 닫힌다고 찡찡대며 물어봤는데, 인풋() 이거 한 번 적으니까 바로 해결되었다 ; 아 킹받아. 도대체 왜 이러는 걸까?
→ 서치하고 서치하고 서치해보니 ‘프로그램이 종료되지 않고 계속 실행되도록 한다’ 이게 맞았다… 디버깅 목적으로 사용된다고 한다. 프로그램이 실행되고 웹 브라우저를 제어하여 특정 작업을 수행하고 바로 종료 안되게 막아준다 ! 이말인거다… 입력 기다리는 동안 프로그램이 계속 실행되니 개발자가 결과를 확인할 떄 자주 쓴다고 한다.
예를 들어 웹 브라우저가 로그인을 시도하고 나서 사용자에게 다음으로 뭘 할건지 물어본다는 것이다. 실제 환경ㅇ에서는 사용 안 하거나, 임시로 사용된다고 한다.
정상적으로 작동할때는 이거 수정해서 굳이 실행할 필요가 없는 입력 대기 없애는 게 맞다 !
이렇게 모든 과정을 완료하고 실행해 보았더니…
이렇게 로그인이 되고 ,,,
이딴 자동입력 방지창이 나오긴 했지만 그래도 나름 성공한 것 같았다! 어질어질하다… 솔직히 셀레니움으로 해보고 싶은게 너무 많아서 고민이다.
‘스크래핑’과 ‘자동화’ 부분이 나한테 너무 잘 맞는다. 딥러닝 쪽으로 가야할까…하다가도 내가 너무 그쪽 분야를 쉽게 생각하는 것 같아 실례가 될까봐 무섭다 ;; 해보고 싶은게 많다. 사실 내가 만들겠다고 설치고 다녔던 ‘야구 시뮬레이터’ 도 결국 bs4를 사용해서 진행했으니까. 저번처럼 키워드 분석하는 스크래핑도 재밌었는데 자동화는 진짜진짜 진짜 더 재밌다 ;;;
CAPCHA 우회 방법이 있다고 스택오버플로우에서 듣기는 했는데… 유료고 무엇보다는 아직 그것을 써먹을만한 프로젝트를 찾지 못했다는 것이다. 좀 더 전문적인 프로젝트를 진행하게 된다면 그거 구매해서 사용해봐도 짱 좋을 것 같다!
이미 정보보안을 위주로 공부하겠다고 마음 먹었고, 구름 정보보안 과정도 신청해놓은 상태기에, 정보보안 위주로 공부하다 OSINT 기법을 공부하기 위해 셀레니움(셀리늄?)을 공부하고 있기는 하지만 나중에 시간이 된다면 좀 더 깊게 공부해보고 싶다 !
내일 공부도 Selenium으로 해야 할지, 아니면 슬슬 Bs4로 넘어가서 공부해도 될지는 모르겠다 ;
from selenium import webdriver
from selenium.webdriver.chrome.service import Service
from selenium.webdriver.common.by import By
from selenium.webdriver.support.ui import WebDriverWait
from selenium.webdriver.support import expected_conditions as EC
import collections
import re
chromedriver_path = "/Users/inseoulmate/Downloads/chromedriver-mac-arm64/chromedriver"
service = Service(chromedriver_path)
driver = webdriver.Chrome(service=service)
articles = []
page = 1
while page <= 60: # Limit data collection to 60 pages
url = f"<https://news.naver.com/main/main.naver?mode=LSD&mid=shm&sid1=100#&date=%2000:00:00&page={page}>"
driver.get(url)
wait = WebDriverWait(driver, 30)
wait.until(EC.presence_of_element_located((By.CLASS_NAME, "sh_text")))
article_number = (page - 1) * 30 + 1
news_items = driver.find_elements(By.CLASS_NAME, "sh_text")
for item in news_items:
try:
press = item.find_element(By.CLASS_NAME, "sh_text_press").text
except:
press = ""
try:
headline = item.find_element(By.CLASS_NAME, "sh_text_headline").text
except:
headline = ""
try:
preview = item.find_element(By.CLASS_NAME, "sh_text_lede").text
except:
preview = ""
try:
link = item.find_element(By.CLASS_NAME, "sh_text_headline").get_attribute("href")
except:
link = ""
article = {
"번호": article_number,
"언론사": press,
"기사 제목": headline,
"미리보기 내용": preview,
"기사 링크": link
}
articles.append(article)
article_number += 1
more_button = driver.find_element(By.XPATH, "//a[contains(@class, 'cluster_more_inner')]")
if "more" in more_button.get_attribute("class"):
driver.execute_script("arguments[0].click();", more_button)
page += 1
else:
break
driver.quit()
text = " ".join([article["기사 제목"] + " " + article["미리보기 내용"] for article in articles])
def extract_keywords(text, num_top_keywords=10):
words = re.findall(r'\\w+', text.lower())
counter = collections.Counter(words)
return counter.most_common(num_top_keywords)
top_keywords = extract_keywords(text, num_top_keywords=10)
print("가장 많이 나온 키워드 Top 10:")
for keyword, count in top_keywords:
print(f"{keyword}: {count}회")
print("\\n기사 목록:")
for article in articles:
print(f"{article['번호']}. {article['언론사']} - {article['기사 제목']} ({article['기사 링크']})")
keywords_str = "가장 많이 나온 키워드 Top 10:\\n"
for keyword, count in top_keywords:
keywords_str += f"{keyword}: {count}회\\n"
with open("top_keywords.txt", "w", encoding="utf-8") as file:
file.write(keywords_str)
articles_str = "기사 목록:\\n"
for article in articles:
articles_str += f"{article['번호']}. {article['언론사']} - {article['기사 제목']} ({article['기사 링크']})\\n"
with open("articles_list.txt", "w", encoding="utf-8") as file:
file.write(articles_str)
코드 전문이다.
지난번에 셀레니움 맛보기로 지니뮤직 순위 스크래핑을 해보았는데, 이번에는 셀레니움가지고 네이버 뉴스를 스크래핑해보았다. 조금 더 기능을 구현하고 싶어서 텍스트 파일로 저장하고 , 가장 많이 나온 키워드들을 찾아 몇 회 나왔는지 정리해보는 과정까지 해보았다
WebDriverWait:WebDriverWait클래스를 이용하여driver객체를 최대 30초까지 기다리며, 해당 시간 내에 By.CLASS_NAME 으로 지정된 "sh_text" 클래스가 웹페이지에 나타날 때까지 기다리도록 한다.
driver.find_elements: 웹페이지에서 "sh_text" 클래스를 갖는 모든 요소들을 찾습니다. 지니뮤직을 스크래핑 했을때와 비슷하게 By.CLASS_NAME을 사용했다.
반복문을 적용해주었다.
article딕셔너리에 정보들을 추가했고, 이 딕셔너리를 articles 리스트에 추가해주었다. 모든 기사의 정보를 담고 있다.
💡 헤드라인 더보기 버튼을 클릭하지 않으면 5개까지만 스크랩이 가능했다. 헤드라인 더보기 버튼을 클릭해야 나머지 5개의 기사가 나왔기 때문이다.
헤드라인 더보기" 버튼 클릭: 페이지의 끝까지 스크롤해서 "헤드라인 더보기" 버튼을 찾아야 했다. 있는 경우도 있었고 없는 경우도 있었기 때문이다. 버튼이 존재하면driver.execute_script메서드를 사용하여 JavaScript를 실행시켜 버튼을 클릭한다. 이렇게 하여 다음 페이지로 이동하여 뉴스를 추가로 스크래핑 하도록 하였다
페이지 수 카운팅: 스크래핑이 끝난 후page변수에 1을 더해서 다음 페이지로 이동하게 해두었다. 정말 많은 페이지가 있었기에 60페이지만 할 수 있도록 하였다. 60장을 모두 스크래핑하면 다음 페이지로 넘어간다.
드라이버를 종료해주었다. 자원을 효율적으로 사용하고 브라우저를 종료해주어야 했기 떄문이다
키워드 분석 및 결과 출력: 모든 기사의 제목과 미리보기 내용을 합쳐서 문자열로 만든 후,extract_keywords함수를 사용하여 가장 많이 등장하는 단어 10개를 찾아낸다. 정규표현식 **re.findall(r'\\w+', text.lower())**을 사용하여 텍스트 데이터에서 단어만 추출하고, 단어들의 빈도를 세는 데에 **collections.Counter()**를 사용했다.
마지막으로 결과를 텍스트 파일로 저장해주었다. 이때 문자열 형식으로 저장해야 했는데, 파일 인코딩은 “UTF-8”로 해주었다.
텍스트 파일에 잘 저장된 모습이다. 1000개 이상 스크래핑해보았다.
오늘자 뉴스에서 제일 많이 나온 단어는 '잼버리' 였다! 잼버리 논란 진짜 많던데... 잘 해결되었으면 좋겠다 !